Overview
The Kafka Connect File Chunk connectors are a fancy way to send a file:
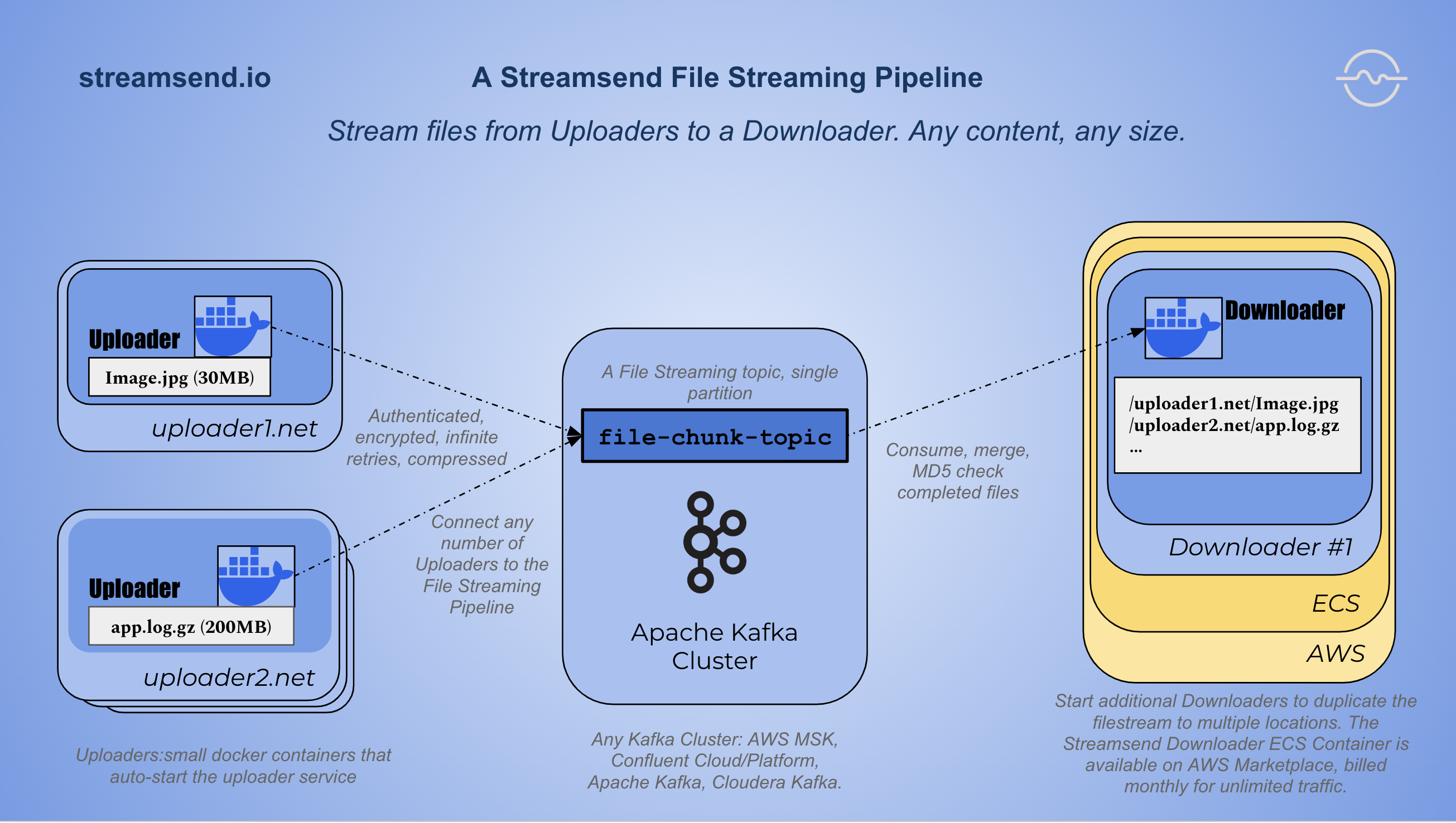
Why Stream Files?
Sometimes it make more sense to stream a file rather than to use send-utilities (such as mv, cp, scp, ftp or curl). An Object Store (generally needed to implement a "claimCheck" pattern) may not be feasible.
Files Alongside Events
For example, if you are an Insurance Provider, you may need to send an updated policy pdf alongside an updateEvent from an updatePolicy microservice.
Infinite Retries
Perhaps you need to send large volumes of images from a remote field-team with a poor network connection; where you want to "click send and forget" and not worry about network service interruptions.
Low Latency
Most file-senders are sequential and serial: chunks of a file are sent in parallel, using Kafka topic partitions and consumer groups.
Benefits of sending files as Streams:
-
binary data as events: smaller, more flexible units of data on the network than sending files
-
automatic retry whenever any transmission failures occur
-
many uploaders sending to one downloader (fan-in)
-
one uploader distributing files to many downloaders (fan-out)
-
strong encryption and authentication
-
virtually unlimited parallel scalability for data uploaders and downloaders
-
Apache Kafka & Kafka Connect: a vibrant open source development community
Demo
Stream large binary files from Singapore to Hong Kong via a Kafka Cluster in Taiwan: https://www.youtube.com/channel/UC8GQcsDExU1tgMUAjALUUSg
Show me with Logfiles
Source Connector
audioRec_2.2MB.mpg: 2200000 bytes, starting chunking
audioRec_2.2MB.mpg: (00001 of 00003) chunk uploaded
audioRec_2.2MB.mpg: (00002 of 00003) chunk uploaded
audioRec_2.2MB.mpg: (00003 of 00003) chunk uploaded
audioRec_2.2MB.mpg: finished 3 chunk uploads
audioRec_2.2MB.mpg: MD5=4fb8086802ae70fc4eef88666eb96d40
Sink Connector
audioRec_2.2MB.mpg: (00001 of 00003) downloaded first chunk
audioRec_2.2MB.mpg: (00002 of 00003) consumed next chunk (1024000 downloaded)
audioRec_2.2MB.mpg: (00003 of 00003) consumed next chunk (2048000 downloaded)
audioRec_2.2MB.mpg: Merge complete (2200000 bytes)
audioRec_2.2MB.mpg: MD5 ok: 4fb8086802ae70fc4eef88666eb96d40
What does a file-chunk connectors pipeline do?
A file-chunk streming pipeline must operate as a pair of connectors where the file-chunk source connector produces messages, and the file-chunk sink connector consumes those messages.
The source connector splits input files into fixed size messages that are produced to a kafka topic.
The sink connector consumes the file chunks and reassembles the file at the target server.
Splitting (or "chunking") input files into events allows files of any size (and of any content type) to be streamed using a file streaming pipline.
A file streaming pipeline is built upon fifteen years of Apache Kafka engineering excellence, including unlimited scalability, low latency, multi-platform compatibility, robust security and a thriving engineering community.
What does a file-chunk connectors pipeline not do?
A file chunk connector pipeline doesnt care what is actually in a file: so it cannot register (or validate) a schema; or convert or unzip contents
It only chunks a file along binary.chunk.file.bytes boundaries: not on any other measure (such as end of line; or object; elapsed time or frames)
A file-chunk pipeline recreates the file: it cannot be used to stream chunks to a different consumer (for example, to a stream processor or to a object store)
Chunking and merging require measurable elapsed time: so while this technique is tunable and potentially very fast; it is not in the realm of ultra-low latency data streaming (for high-frequency trading or any microsecond (or indeed millisecond) requirements)